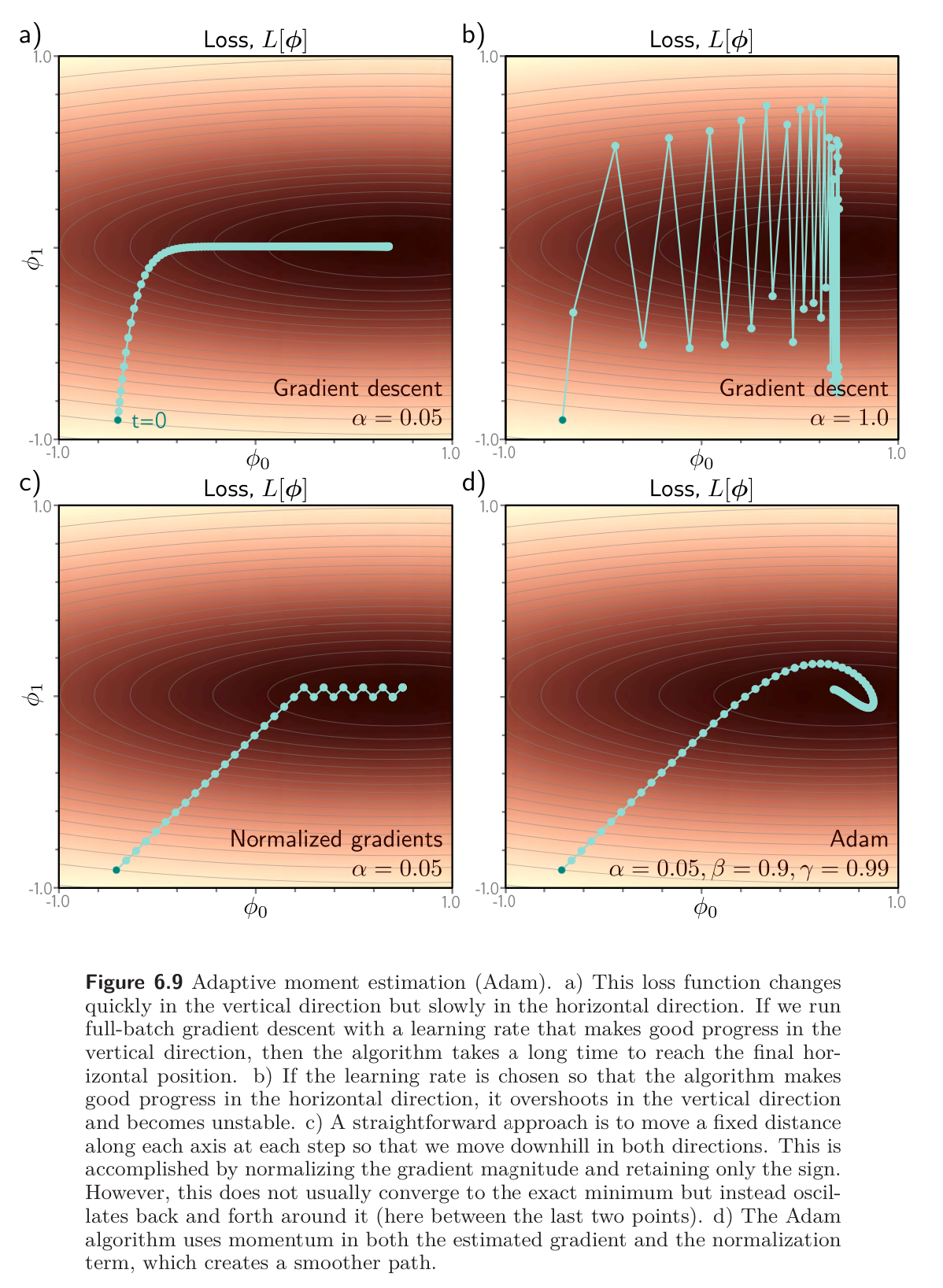
A big weakness of gradient descent with a fixed step size is that it makes large adjustments to parameters associated with large gradients (where perhaps we should be more cautious) and small adjustments to parameters associated with small gradients (where perhaps we should explore further). When the gradient of the loss surface is much steeper in one direction than another, it’s difficult to choose a learning rate that makes good progress in both directions and is stable.
Normalized gradients
A straightforward approach is to normalize the gradients so that we move a fixed distance (governed by the learning rate) in each direction.
To do this, we first measure the gradient and the pointwise squared gradient :
Then we apply the update rule:
where:
- The square root and division are both pointwise
- is the learning rate
- is a small constant that prevents division by zero
Essentially: the term is the squared gradient, and its positive root is used to normalize the gradient itself, so all that remains is the sign in each coordinate direction. The result is that the algorithm moves a fixed distance along each coordinate, where the direction is determined by whichever way is downhill.
This simple adjustment makes good progress in both directions but will not converge until it happens to land exactly at the minimum, instead, it will bounce around the minimum.
Adam
Adaptive moment estimation, or Adam, takes the idea of normalized gradients and adds momentum to both the estimate of the gradient and the squared gradient:
where and are the momentum coefficients for the two statistics.
Initialization bias correction: Using momentum is equivalent to taking weighted average over the history of each of these statistics. At the start of the procedure, all the previous measurements are effectively zero as we start with , resulting in unrealistically small estimates. Consequently, we modify these statistics using the rule:
Since and are in the range , the terms with exponents become smaller with each time step, the denominators become closer to one, and this modification has a diminishing effect.
- Imagine trying to compute an average from just a few data points – we’d expect some bias just because we don’t have enough samples yet. This bias correction acts like a “smart guess” of what the average would have been with a longer history.
Finally, we update the parameters as before, but with modified terms:
The result is an algorithm that can converge to the overall minimum and makes good progress in every direction in the parameter space.
Note that Adam is usually used in a stochastic setting where the gradients and their squares are computed from mini-batches:
so the trajectory is noisy in practice.
The gradient of neural network parameters can depend on their depth in the network; Adam helps compensate for this tendency and balances out changes across the different layers. In practice, Adam also has the advantage of being less sensitive to the initial learning rate because it avoids situations like those in figure 6.9 a-b (above), so it doesn’t need complex learning rate schedules.
Notes
Adam has become the default method for managing step sizes in neural networks. It combines the ideas of Momentum (ML) and adadelta.
- Take the average of the gradient
- Moderate step size based on magnitude of gradient
We start by writing the moving averages of the gradient and squared gradient, which reflect estimates of the mean and variance of the gradient for weight :
A problem with these estimates is that, if we initialize , they will always be biased (slightly too small). So we will correct for that bias by defining:
Note that is raised to the power of and likewise for . To justify these corrections, note that if we were to expand in terms of and the coefficients would sum to However, the coefficient behind is and since , the sum of coefficients of non-zero terms is , hence the correction. The same justification holds for .
Now, our update for weight has a step size that takes the steepness into account (like Adadelta) but also tends to move in the same direction (like momentum). The authors of adam like setting:
Although we now have even more parameters, adam is not highly sensitive to their values. Even though we now have a step-size for each weight, and we have to update various quantities on each iteration of gradient descent, it’s relatively easy to implement by maintaining a matrix for each quantity in each layer of the network.