Consider a scalar function that depends on some variable . Suppose we want to minimize with respect to , i.e.
We can use gradient descent:
where is the gradient of with respect to , and is the learning rate.
Pseudocode
- Initialize .
- Construct the expression graph for .
- Until convergence:
- Evaluate at
- Set gradients to zero (i.e. .grad = 0)
- Propagate derivatives down (increment .grad)
- Update .grad
Neural Learning
We use the same process to implement error propagation for neural networks, and we optimize with respect to the connection weights and biases.
To accomplish this, our network will be composed of a series of layers, each layer transforming the data from the layer below it, culminating in a scalar-valued cost function.
There are two types of operations in the network:
- Multiply by connection weights (including adding biases)
- Apply activation function
Finally, a cost function takes the output of the network, as well as the targets, and returns a scalar.
Let us consider this small network:
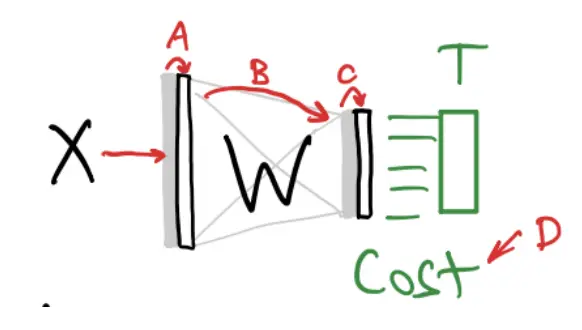
Given dataset :
These are all functions that transform their input.
Each layer can be called like a function:
Each layer, including the cost function, is just a function in a nested mathematical expression:
Neural learning is:
We construct our network using objects from our AD classes (Variables and Operations) so that we can take advantage of their backward() methods to compute the gradients.
Then, we take gradient steps:
E.zero_grad()
E.backward()
Matrix Autodiff
To work with neural networks, our AD library will have to deal with matrix operations.
Matrix Addition
Suppose our scalar function involved a matrix addition:
What is and ?
As we previously, within the plus operation method +.backward(s), we need to call the following commands

Matrix Multiplication
Suppose our scalar function involved a matrix multiplication:
Then: