Simulated annealing is a trajectory search method inspired by the thermodynamic cooling of materials. A temperature parameter controls the randomness of motion, allowing us to converge from exploration to exploitation.
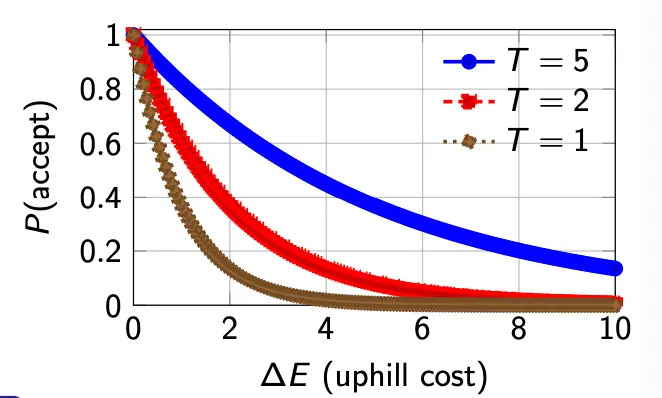
SA uses a probabilistic rule (Boltzmann acceptance probability):
where is our cost function. That is, we always accept improving moves, and sometimes accept non-improving moves.
The temperature parameter governs this:
- high → More exploration (accept more uphill moves)
- low → More exploitation (mostly greedy)
Cooling Schedules
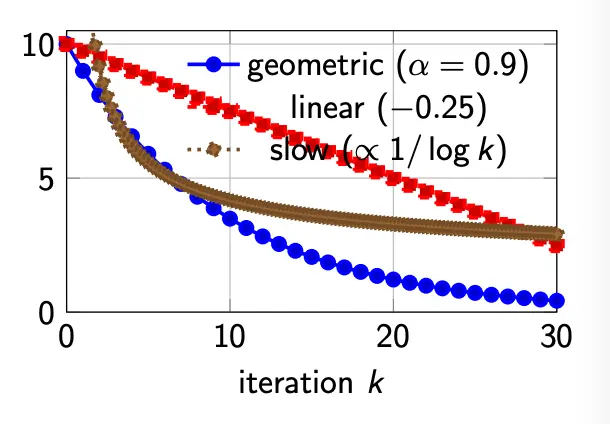
is not held constant, but follows a schedule, such that we explore early and then exploit later. We don’t want a schedule that is too fast (basically becomes hill climbing early), or one that is too slow (wastes time wandering).
Common schedule:
- Geometric: , where .
- This is a practical default.
- Linear: .
- This is easy to reason about
- Very slow: .
- This provides some theoretical guarantees but is often too slow.
Pseudocode

Example
We aim to minimize energy . Let our current , with temperature .
We take a random move in the neighborhood and sample a neighbor with .
Then:
and
Thus, even the move is worse, it is likely accepted due to the high . This enables barrier crossing early in the run.
For , what is for different temperatures?

Thus, we see that cooling converts from exploration (many uphill moves allowed) to exploitation (almost greedy).
Practical Considerations
To make simulated annealing work better in practice, we do:
- Adaptive neighborhood control
- Reheating and strategic restarts:
- Detect stagnation: no improvement over iterations
- Increase temperature temporarily: , with
- Allows escape from a deep local minima without discarding accumulatd structure
- Multiple trials per temperature level
- Perform neighbor evaluations at each temperature
- Reduces sensitivity to unlucky single moves
Convergence Theory
The behavior of SA with constant temperature can be modeled using a Markov Chain. This is pretty intuitive – at a fixed , SA defines a stochastic transition where the next state only depends on the current state, satisfying the Markov property.
It has been shown that under constant temperatures and as long as it’s possible to find a sequence of exchanges that will transform any solution to another with non-zero probability, the process converges, independent of the starting solution.
With non-constant temperature, we have a non-homogeneous Markov chain. This converges if the temperature is reduced to zero slowly with a specific logarithmic form (that very slow cooling schedule) and the number of iterations at each temperature is large (exponential in terms of size).
SA and Machine Learning
- Reinforcement Learning (RL) aims to maximize expected future reward. Rewards depend on sequences of past actions, not isolated decisions. The system evolves via a probabilistic state transition function driven by the current state and chosen action. Actions represent control decisions that affect both immediate reward and future system states. This coupling makes RL optimization highly non-trivial. Adaptive Simulated Annealing is used to optimize RL parameters, leading to improved control policies.
- Deep learning-enabled SA for topology optimization. Topology optimization is a high-dimensional, stochastic optimization problem requiring millions of expensive finite-element evaluations. The computational cost of classical SA becomes prohibitive for large-scale designs. A DNN is integrated with Generative Simulated Annealing (GSA) to approximate the objective function. GSA uses the DNN for fast evaluation, while newly generated solutions are used to continually retrain the DNN. The DNN–GSA loop converges to high-quality solutions with over two orders of magnitude reduction in computational cost.