Clustering problem: Given objects (each could be a vector of features), group them in groups in such a way that all objects in a group have a “natural” relation to one another, and objects not in the same group are somehow different.
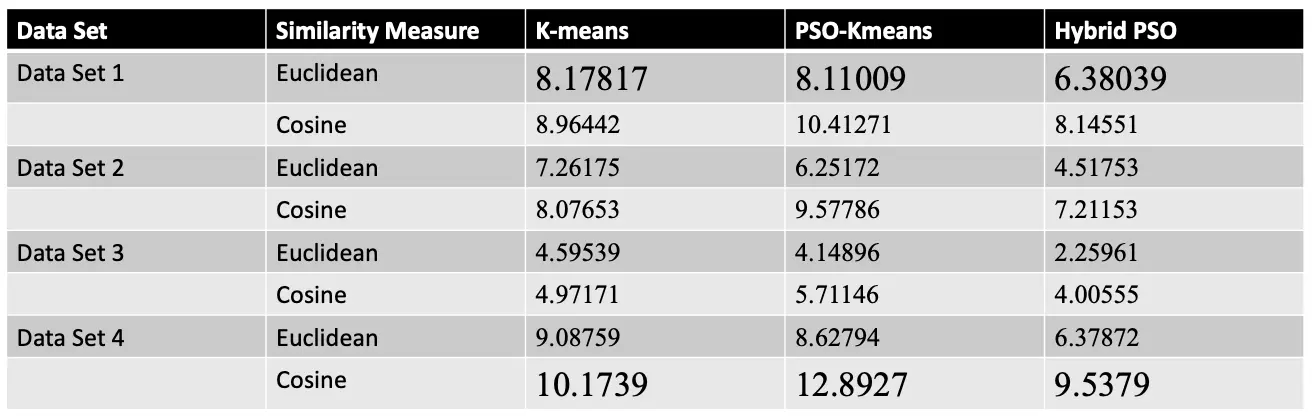
K-means
The prototypical clustering algorithm is -means:
- Initialize cluster centers
- Repeat:
- Distribute objects among clusters using similarity measure and satisfying performance index
- Compute new cluster centers until no change in centers.
This is typically applied with a number of different conditions and then we pick the best solution.
PSO Clustering
- Initialize each particle as random cluster centers.
- For iterations = 1 to max:
- For all particles :
- For all patterns in the datset:
- Calculate Euclidean distance of with all cluster centroids
- Assign to the cluster that has the nearest centroid to
- Calculate the objective function for the current centers and assignment
- For all patterns in the datset:
- Find the personal best and global best position of each particle
- Update the cluster centroids according to PSO velocity and position updates
- For all particles :
Hybrid PSO-K-means
- Start PSO clustering process until the max number of iterations is exceeded
- Inherit clustering result from PSO as the initial centroid vectors of -means
- Start -means process until max number of iterations
For PSO, is initially set as 0.72, and . is reduced by 1% at each generation to ensure good convergence.