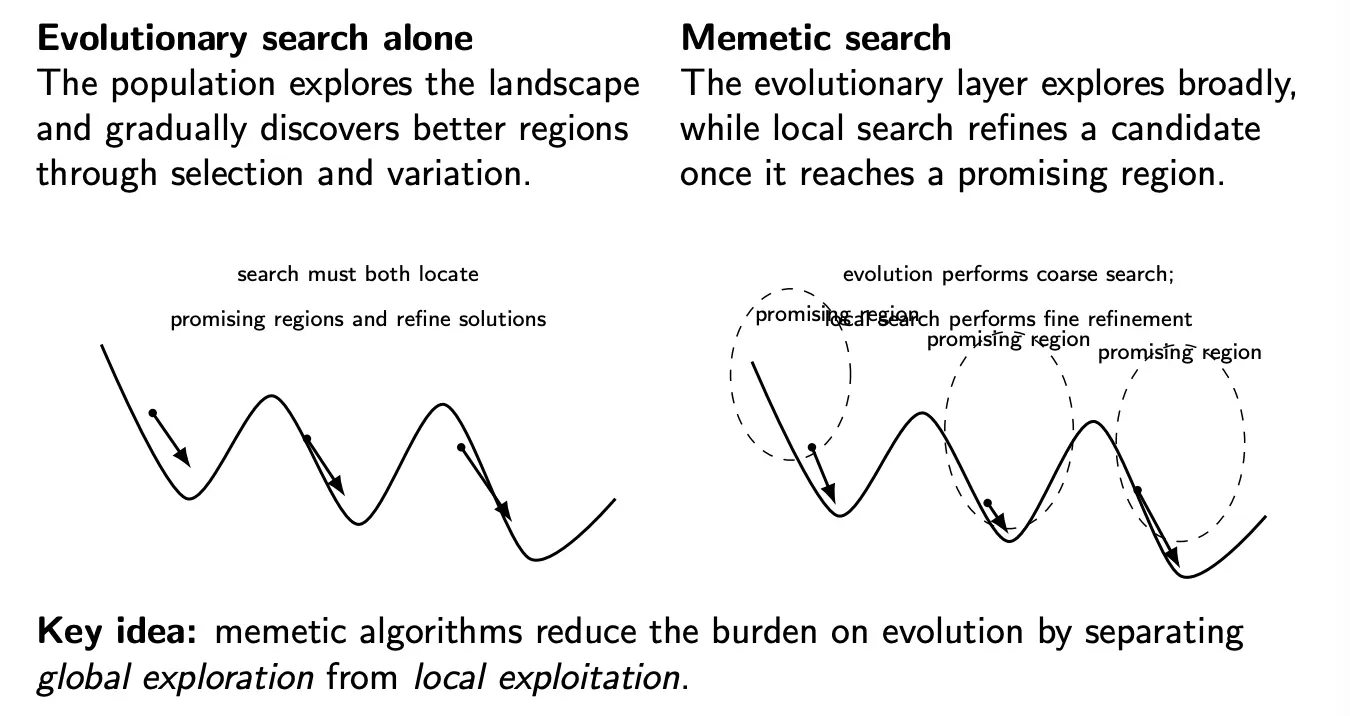
Memetic algorithms combine global evolutionary search with local improvement.


Essentially, the idea is that evolutionary algorithms are more random than necessary near an optimum, as the mutation/recombination may be too coarse. On the other hand, local search methods and gradient descent are good at this type of thing but might get stuck in local optima.
For a differential problem, the simple abstract form of memetic algorithms is:
where provides stochastic exploration and provides local descent.
In algorithmic form:

Formally, if denotes the evolutionary variation operator and the local search operator, a pure evolutionary algorithm would be:
A memetic algorithm inserts the local search:
We can also think of EA as providing guidance to find basins to enter, and local search as determining where inside that basin is the lowest point.
Analysis
Consider the simplified memetic update:
The candidate evolves candidate solutions , but convergence should be analyzed relative to an optimum . Define the error state:
Then:
So, for convergence we want:
Near a smooth local optimum , the gradient can be linearized:
where is the Hessian at .
So the local dynamics become:
We can either do a deterministic contraction to go toward the optimum:
or do exploratory forcing to re-inject diversity and allow basin transitions. This is the local dynamical interpretation of memetic search.
Quadratic Example and Analysis





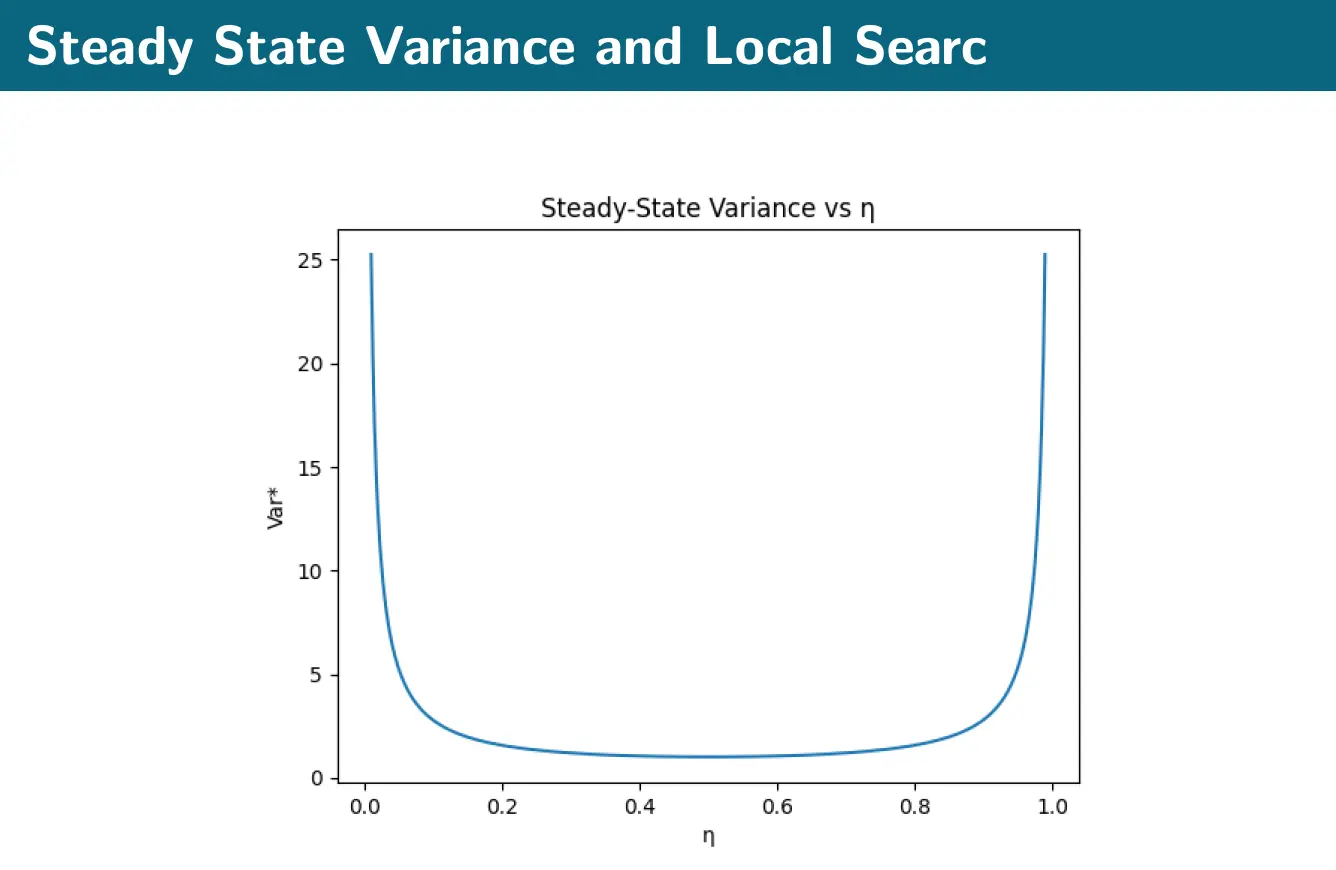
Thus, we can see that the parameters and define the search regime: sets the noise level (exploration), and controls contraction (refinement).
- Large , small gives highly exploratory behavior, with weak refinement. This results in large steady-state variance.
- Small , moderate gives stronger local exploitation. This gives tighter concentration, with variance limited below by .
- If we set to be too large, we can get unstable behavior.
Scheduling
Naively, we can apply local search every generations:
Frequent local search gives strong exploitation but is expensive. Sparser scheduling means that more exploration is retained, with lower cost, but with the trade-off of slower local improvement.
Adaptive schedules
A fixed local-search policy might be suboptimal throughout the run. We can adapt the memetic intensity over time, such that early generations emphasize exploration, and later generations increase local refinement. Examples:
- Increase local-search depth as diversity decreases
- Decrease memetic intensity when the population starts collapsing too quickly
Selection
What individuals should receive local search?
Let denote the selected subset of individuals that receive local search.
- If we want this to be all offspring, we set . This gives the strongest exploitation but also has the strongest collapse risk.
- If we want elites only, we do . This concentrates effort on promising regions.
- We can also do a random subset . This spreads improvement more broadly.
Depth
If local search is applied repeatedly, we can write:
where is the local-search depth.
If we have , that’s just one corrective local step. Moderate gives more meaningful refinement, while very large means near-full local convergence.
But deeper local search means high cost:
Thus, depth controls a trade-off between better local precision and greater computational burden.
Lamarckian vs. Baldwinian
There are two conceptually different ways that local search can be integrated into evolution.
In Lamarckian learning, the improved solution directly replaces the genotype.
This transfers acquired improvement directly.
In Baldwinian learning, the genotype is unchanged but its evaluated quality refletcs local improvement:
This rewards genotypes that can improve well.
Applications/Examples
One-Dimensional Minimization



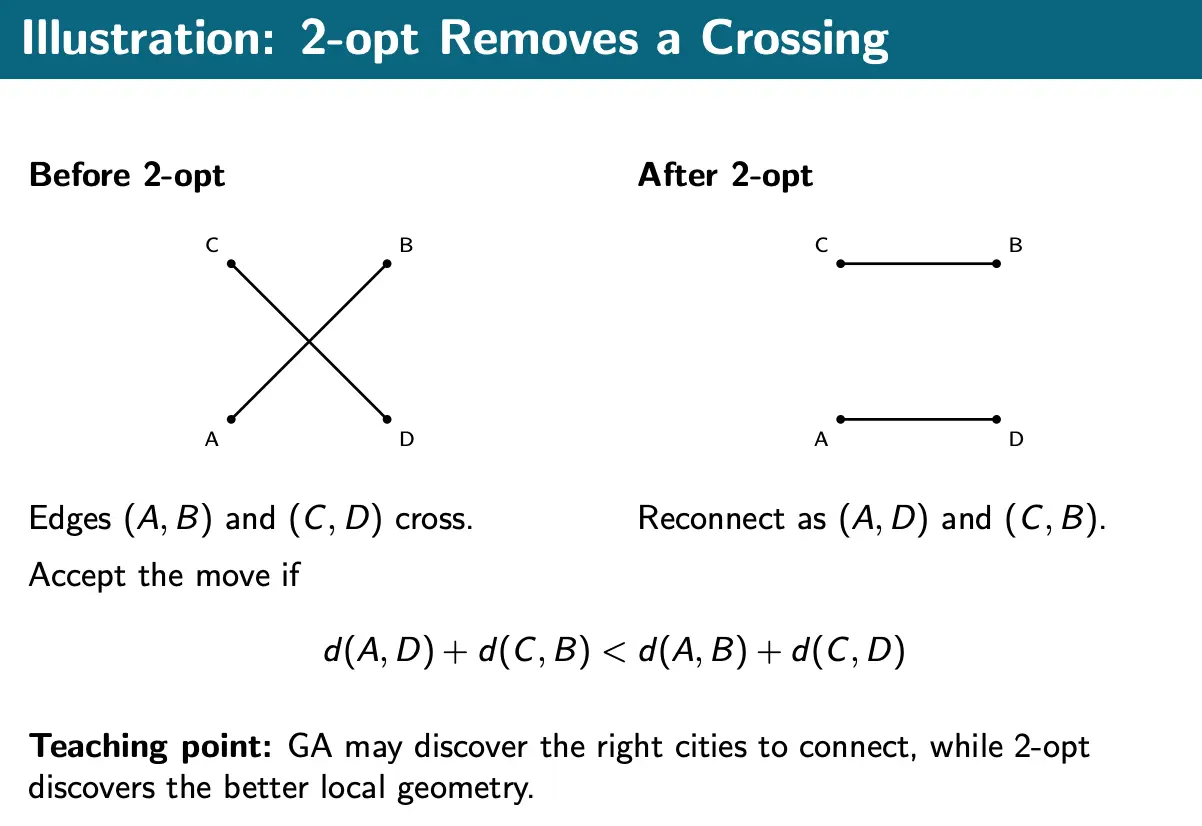
Combinatorial Example: TSP


Neural Networks with Memetic Search


Cost
Let be the population size, be the local search depth, and be the cost of one fitness evaluation. A rough per-generation model is:
where is the subset receiving local search.
This highlights a practical fact: Memetic algorithms often use fewer generations, but each generation is more expensive. So, they are attractive when better solutions justify more effort per candidate