We’ve seen that vectors can be used to represent inputs and outputs:
When it comes to word representations, we can create a vocabulary: the set of all words encountered in a dataset. We can order and index the vocabulary and represent words using one-hot vectors. Let be the th word in the vocabulary:
where is the number of words in our vocabulary. The vector is the one-hot encoding of the word
How do we handle the semantically similar words?
- “AMATH 449 is interesting” vs. “AMATH 449 is fascinating”
We would like to find a different representation for each word that incorporates their semantics.

Predicting Word Pairs
One way to do this is by using the fact that some words often occurs together (or nearby) in sentences.
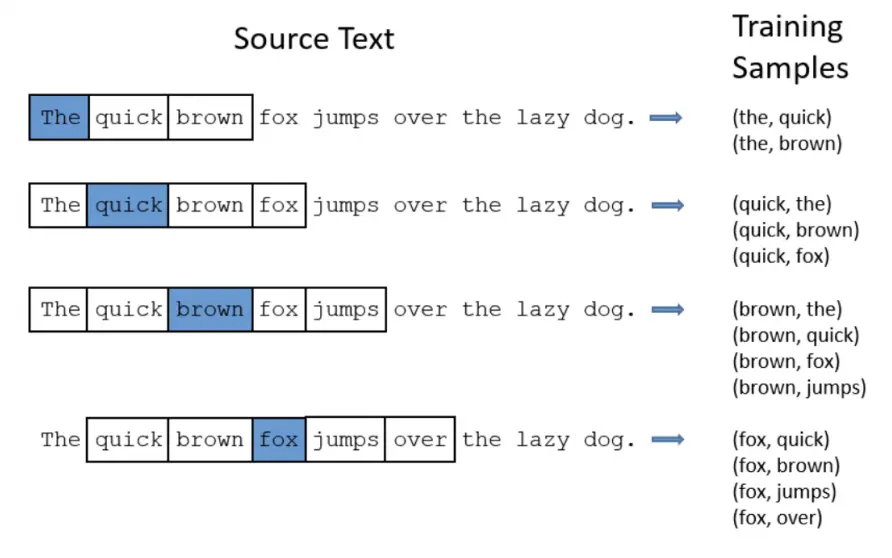
Consider the text: “The scientist visited Paris last week, enjoying the city’s famous museums.”
For the purposes of this topic, we will consider “nearby” to be within a fixed window size .
In our example, nearby the word “last” with : “The scientist visited Paris last week, enjoying the city’s famous museums.” This gives us the word pairings: (week, Paris), (week, last), (week, enjoying), (week, the).
These word pairings help us understand the relationships between words based on their co-occurrence in text.
We can then use a neural network to predict these word co-occurrences. It takes one-hot word vector as input:
and output is the probability of each word’s co-occurrence. We can interpret the output as a distribution over the one-hot vocabulary:
Then equals the probability that is nearby. The output layer uses a softmax activation function.
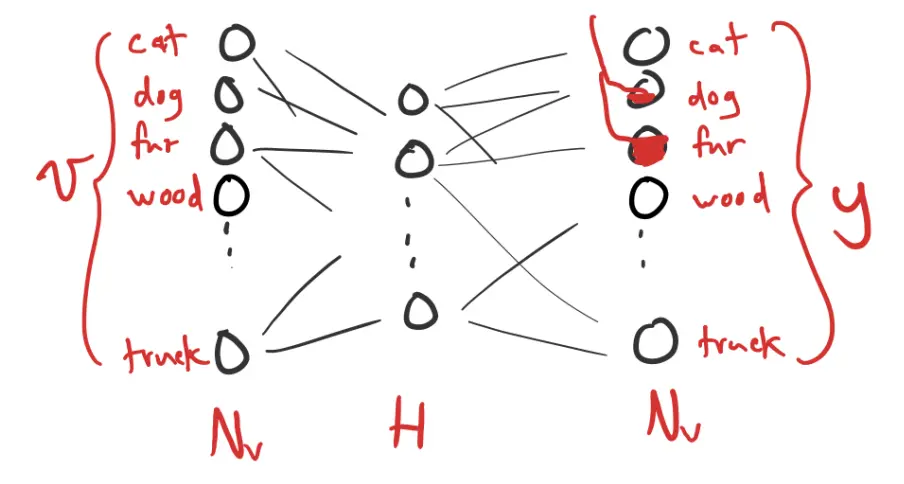
Because the hidden layer is smaller than the input/output dimension, it “squeezes” to force a compressed representation, requiring similar words to take on similar representation. This is called an embedding.
word2vec
word2vec is another popular embedded strategy for words/phrases/sentences. On top of the co-occurrence approach, we:
- Treat common phrases as new words (e.g., “New York” is one word)
- Randomly ignores very common words (e.g., for “the car hit the post on the curb”, only 20/56 word pairs don’t involve “the”)
- Negative sampling: backpropagate only some of the negative cases.
Embedding Space
The embedding space is a relatively low-dimensional space where similar inputs are mapped to similar locations.
Why does this work? Words with similar meanings will likely co-occur with the same set of words, so the network should produce similar outputs, and therefore have similar hidden-layer activations.
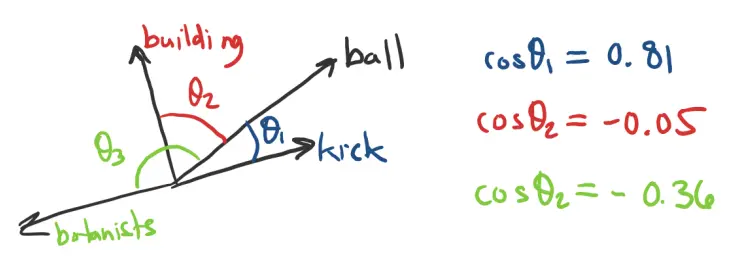
Cosine Similarity
The cosine angle is often used to measure the distance between two vectors in the embedding (latent) space.
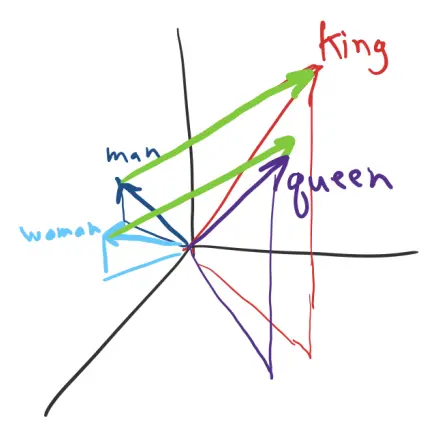
Vector Arithmetic with Embeddings
To some extent, we can do vector addition on embedding representations.