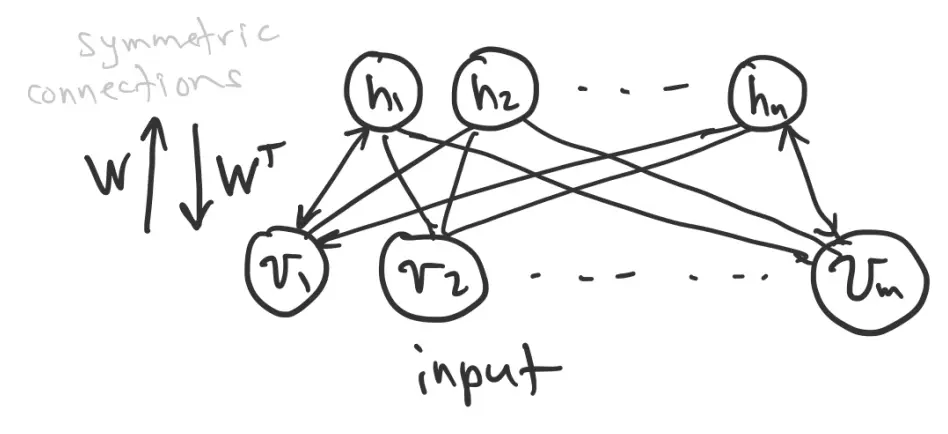
An RBM network consists of:
- A “hidden layer”:
- A “visible layer”: , because this layer interacts with the environment.
Note that each node is binary, so it is either on (1) or off (0). The probability that a node is on depends on the states of the nodes feeding it, and the connection weights.
Connections between layers are symmetric, represented by weight matrix .
Together, and represent the network state. For example, a single network state could be:
RBM energy
Similar Hopfield Networks, an RBM is characterized by an energy:
- is a bias for the visible units, is a bias for the hidden units
- lowers the energy when connected visible and hidden nodes are both on
- lowers the energy of states where biased units are on
Like many processes in nature, we want to find the minimum energy.
Consider the “energy gap”, the difference in energy when we flip a visible unit from off to on:
- If , then , so “on” is lower energy and we set
- If , then , so “off” is lower energy and we set
Similarly, for a hidden unit:
The energy gap of each node depends on the states of other nodes, so finding the minimum energy state requires some work. One strategy is to visit and update the nodes in random order (like Hopfield). We can do better since our network is bipartite (hence the “Restricted”). The visible units only depend on the hidden units, and vice versa, so we can update one whole layer at a time.
This is still a local optimization method, so we can still get stuck in local optima. To avoid this, we use stochastic (random) neurons. Each neuron is on or off according to a probability that is established by its input current:
where is a temperature parameter. This idea comes from statistical mechanics. Essentially, higher temperature makes the sigmoid curve flatter so that there is more movement back and forth between the states.
Let’s say we want to find out whether neuron is on:
- Evaluate its probabilities
- For :
- If :
- Else:
This produces a .
This is basically a Bernoulli Distribution sampling process.
If we let our network run freely using the logistic function to compute the probability that each neuron is 1 vs. 0, starting with some initial state , we project up to , project it down to get , project back up, etc.
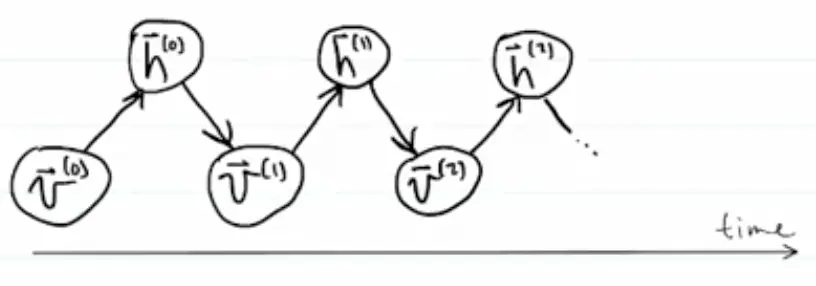
We will eventually visit all possible network states, but not with equal probability. Instead we will visit state with probability
where
This is a Gibbs/Boltzmann distribution over network states.
If
then
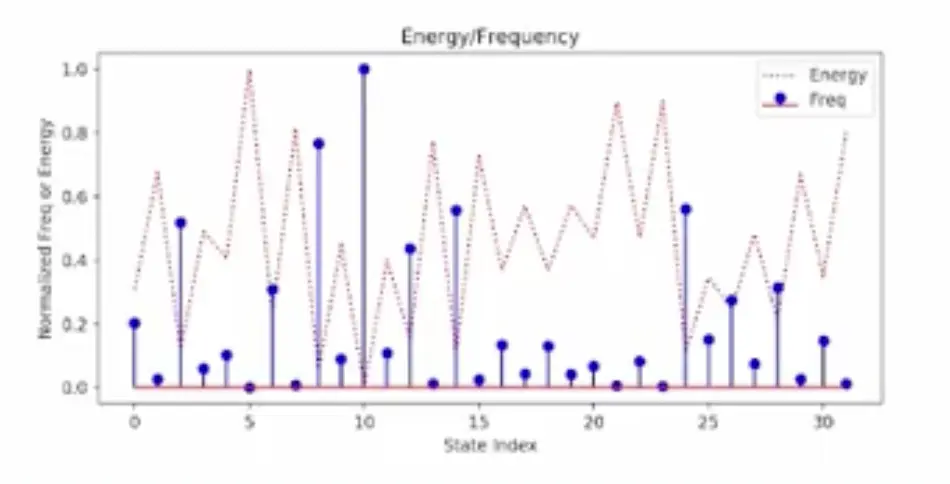
Lower energy states are visited more frequently. This is known as the Boltzmann Distribution.
Example with 4 visible nodes and 2 hidden nodes (32 net states):
Training an RBM as a Generative Model
Suppose we have inputs . We want an RBM to behave as a generative model such that
Let
for a given fixed . Then:
Thus, we can decompose the loss into .
To do gradient descent, we need to find the gradients.
Gradient of
- is the distribution of conditioned on the fixed
Gradient of
- is the joint distribution over and
Gradient for
What is the gradient of ? Consider .
Recall:
Then:
Term 1. This is the expected value under the posterior distribution. We clamp visible states to :
or, in vector form,
Note that this calculates the hidden Bernoulli probabilities; it does not actually give us the binary hidden units.
Then
Computing for all the weights at once:
Term 2. This is the expected value under the joint distribution:
We could estimate this by running the network freely for a lot of iterations and sampling the results. In practice, a single network state is often used.

We start with the fixed and project it up to get hidden probabilities. Then we sample to get a binary hidden state . We project down to get a new visible state, and then project up again. Using one such sample, we approximate:
To update all weights in :
We call the up pass (from visible to hidden) recognition. We call the down pass (hidden to visible) generation.
Contrastive Divergence for Training RBMs
This algorithm is based on a comparison between the original input and how well it can be reconstructed from the resulting hidden-layer state.
We are given an input pattern with visible nodes and hidden nodes.
1. Recognition pass 1. Given a visible pattern , we compute hidden probabilities:
where
2. Compute term 1 (the co-occurrence statistics: how many times and are both on simultaneously):
3. Generative pass. Sample the hidden nodes:
Projecting down gives the visible pre-activation:
Computing the Bernoulli probabilities of the visible units given the hidden state:
Sample
4. Recognition pass 2.
We can sample
or use directly.
5. Compute term 2 co-occurrence statistics:
6. Update weights:
This is essentially comparing the co-occurrence statistics for the input () with the co-occurrence statistics for the reconstruction ().
Update biases:
Training algorithm:
for each temperature T = 20, 10, 5, 2, 1
for each of 400 epochs
for each V batch (visible patterns from data)
add some noise (optional)
project up: V -> H1, collect S1
project down and up: H1 -> V1 -> H2, collect S2
update weights and biases