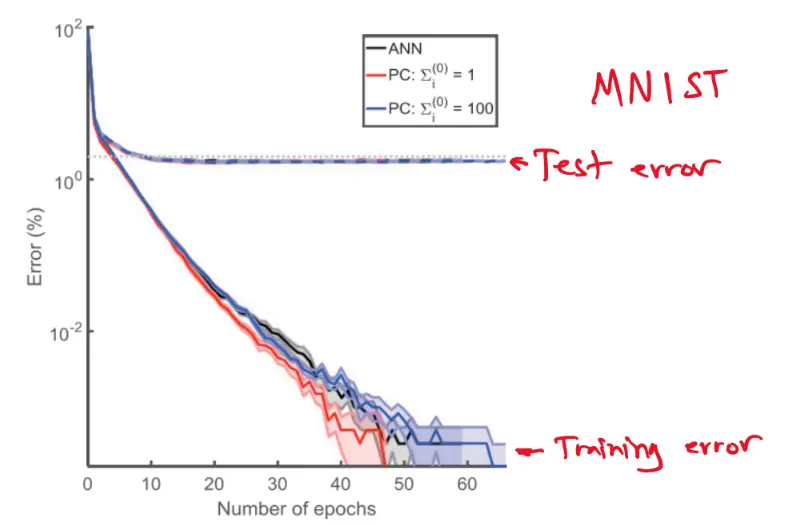
Can a real brain do backprop? We are constrained by physics and chemistry:
- Synaptic updates can only be based on local info
- Connection weights cannot be copied to other connections
In backprop, the error gradients are somehow propagated down through the network.
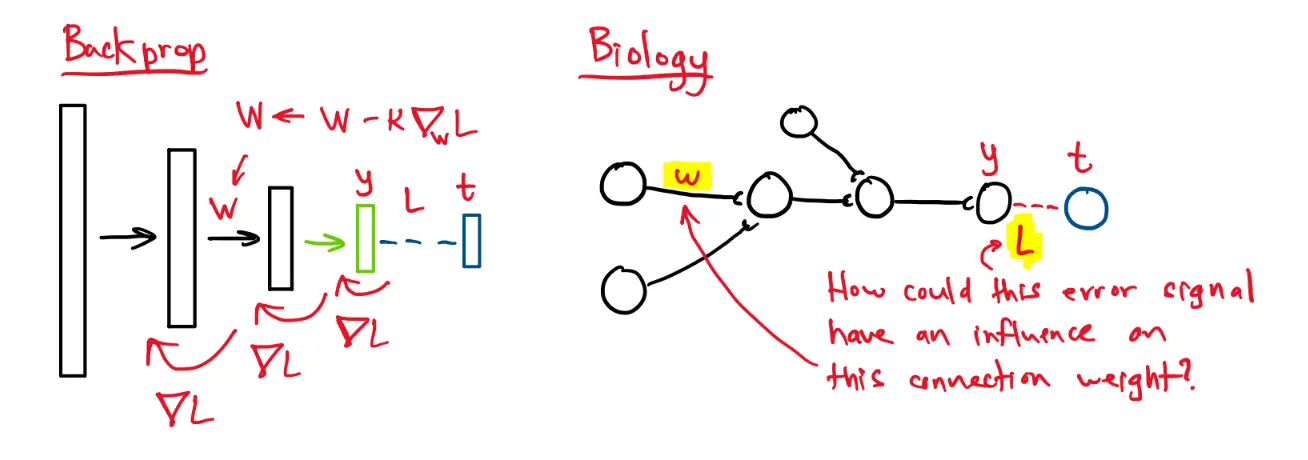
There are some architectures that implement something like backprop, but in a biologically plausible way.
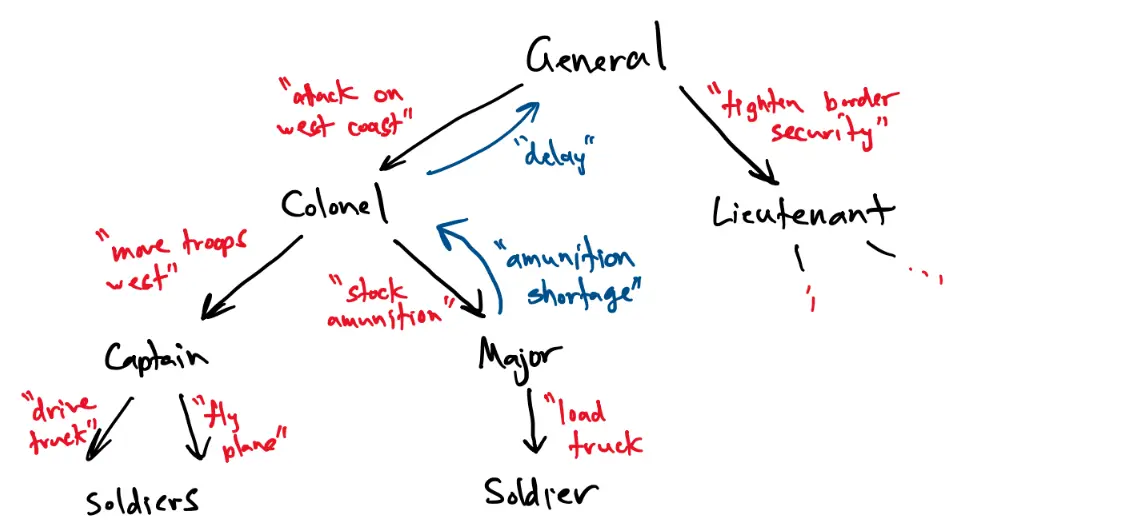
In predictive coding, predictions/commands are sent one way through the network, and errors/deviations are sent the other way. A good way to think about this is a military chain of command:
Comparing feedforward networks and predictive coding networks:
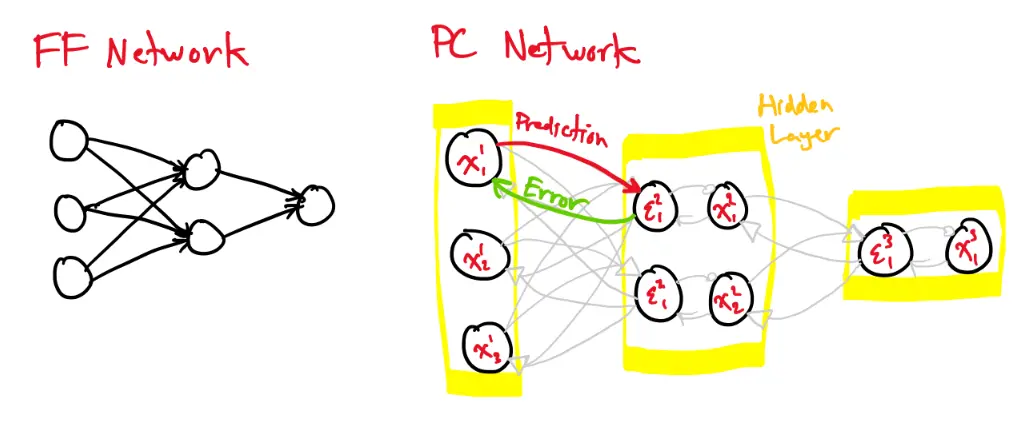
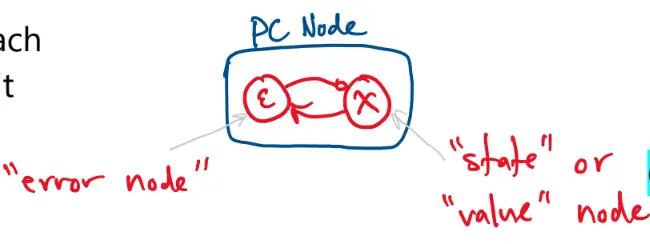
In a PC network, each hidden node is split into two parts: an error node and a state/value node.
Let’s represent a whole layer as a single circle:
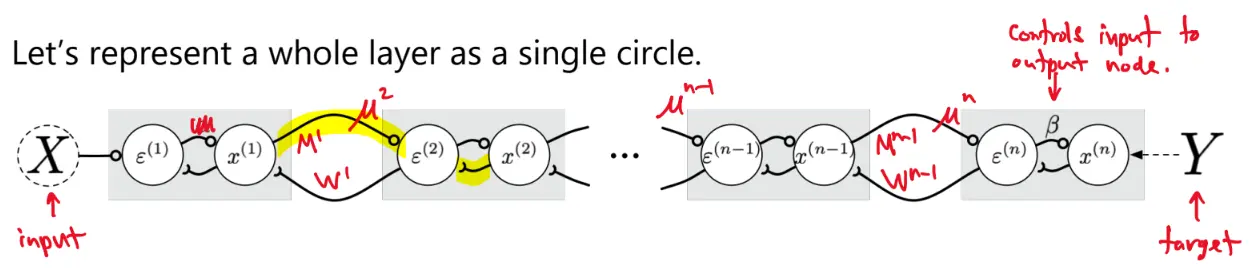
is the prediction being sent up to layer :
- For now, assume .
The error node is the difference between and . It has dynamics:
At equilibrium, we get:
The goal for training the PC network is as follows. Given dataset :
where
Consider . Assume is normally distributed:
Hopfield function:
- Recall that
now we show that the network activity acts to decrease the Hopfield energy.
Consider , noting that appears in and . Then:
Thus, gradient descent gives us:

Training
To train the network, we clamp the input on both ends:

We then hold those inputs and running the network to equilibrium.
At equilibrium:
Running to equilibrium allows all the parts of the network to interact. At equilibrium, we have:
Then:
or
Link to Backprop
Starting with the top gradient:

But we also derived that, at equilibrium
Comparing to the backprop formulas:
Thus, is the gradient of the output error with respect to the prediction .
Updating weights
Consider . We have
Likewise:
Therefore:
- These learning rules only use info from nodes adjacent to the connection.
These weight updates formulas are the same type of “delta” used in backprop:
The time constant for the weights is larger than the time constant for the nodes . This allows the value nodes and error nodes to converge to equilibrium faster, setting up the pieces needed for the weight updates. The full system of differential equations is:
Testing
To run it, we just clamp the input and run the network to equilibrium. Once at equilibrium, is the network’s output.