This is similar to the Instruction Decode Cycle or the Consumer Model.
The CPU requests things like the address in memory, whether this transfer is for a read or write, and the data itself. Once memory receives the request it must respond. However, the CPU is not connected to every single location in memory, and must interact with a memory “controller” via address, data, and control lines.
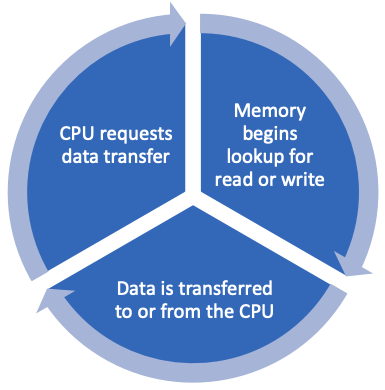
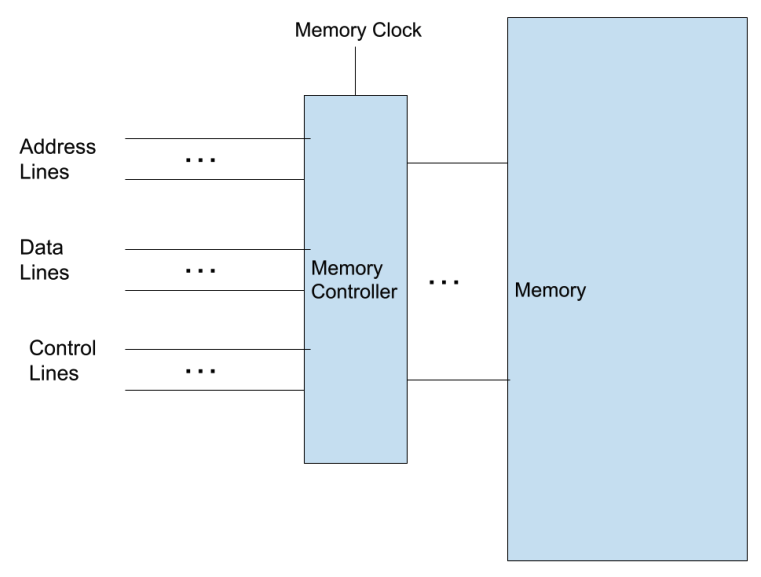
This introduces a bottleneck – we can only transfer as much data as we have data lines for, we must rely on the memory controller and its clock. If we have large memories we might have a hierarchy of of controllers, each writing to only a portion of the entire memory. To ease this bottleneck, caching is used.