Problem 6.1
Show that the derivates of the least squares loss function in equation 6.5 are given by the equations in 6.7.
Each loss component:
Derivatives:
Problem 6.2
A surface is guaranteed to be convex if the eigenvalues of the Hessian are positive everywhere. In this case, the surface has a unique minimum, and optimization is easy. Find an algebraic expression for the Hessian matrix,
for the linear regression model. Prove that this function is convex by showing that the eigenvalues are always positive. This can be done by showing that both the trace and determinant of the matrix are positive.
We have:
Top left :
Bottom left ():
Top right ():
Bottom right ():
So the result for a single point is:
And the Hessian of the total loss is:
The trace is positive:
The determinant is:
Thus, the surface is convex.
Problem 6.3
Compute the derivatives of the least squares loss with respect to the parameters and for the Gabor model.
Let:
Then, we have
where .
First, we can find:
using the product rule and chain rule.
So:
and
Because , for each of the parameters, we have
So:
and
Problem 6.4
The logistic regression model uses a linear function to assign an input to one of two classes . For a 1D input and a 1D output, it has two parameters, and , and is defined
where is the logistic sigmoid function.
- (i) Plot against for this model for different values of and and explain the qualitative meaning of each parameters.
- (ii) What is a suitable loss function for this model?
- (iii) Compute the derivatives of this loss function with respect to the parameters.
- (iv) Generate ten data points from a normal distribution with mean and standard deviation and assign them to label . Generate another ten data points from a normal distribution with mean and standard deviation and assign these the label . Plot the loss as a heatmap in terms of the two parameters and . (v) Is this loss function convex? How could you prove this?
(i) controls the location of the centerpoint of the sigmoid function (), controls the slope of the transition.
(ii) Binary cross-entropy loss:
(iii) Derivatives of the sigmoid function are:
It follows that the derivatives of the loss function are
and
(iv)
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
# Generate data
x0 = np.random.normal(-1.0, 1.0, 10)
y0 = np.zeros(10)
x1 = np.random.normal(1.0, 1.0, 10)
y1 = np.ones(10)
x = np.concatenate([x0, x1])
y = np.concatenate([y0, y1])
# Sigmoid and loss
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def loss(phi0, phi1):
z = phi0 + phi1 * x
p = sigmoid(z)
eps = 1e-12
p = np.clip(p, eps, 1 - eps) # Keep p from exact 0 or 1 to prevent overflow
return -np.sum((1 - y) * np.log(1 - p) + y * np.log(p))
# Grid
phi0_vals = np.linspace(-4, 4, 200)
phi1_vals = np.linspace(-4, 4, 200)
loss_grid = np.zeros((len(phi1_vals), len(phi0_vals)))
for i, phi1 in enumerate(phi1_vals):
for j, phi0 in enumerate(phi0_vals):
loss_grid[i, j] = loss(phi0, phi1)
# Plot
plt.figure(figsize=(7, 6))
plt.imshow(
loss_grid,
extent=[phi0_vals.min(), phi0_vals.max(), phi1_vals.min(), phi1_vals.max()],
origin="lower",
aspect="auto",
)
# Add level curves (contours)
min_loss = np.min(loss_grid)
max_loss = np.max(loss_grid)
contour_levels = np.linspace(min_loss, max_loss, 15)
plt.contour(
phi0_vals,
phi1_vals,
loss_grid,
levels=contour_levels,
colors='white',
alpha=0.7,
linewidths=0.5
)
plt.colorbar(label="Loss")
plt.xlabel(r"$\phi_0$")
plt.ylabel(r"$\phi_1$")
plt.title("Binary Cross‑Entropy Loss Surface")
plt.show()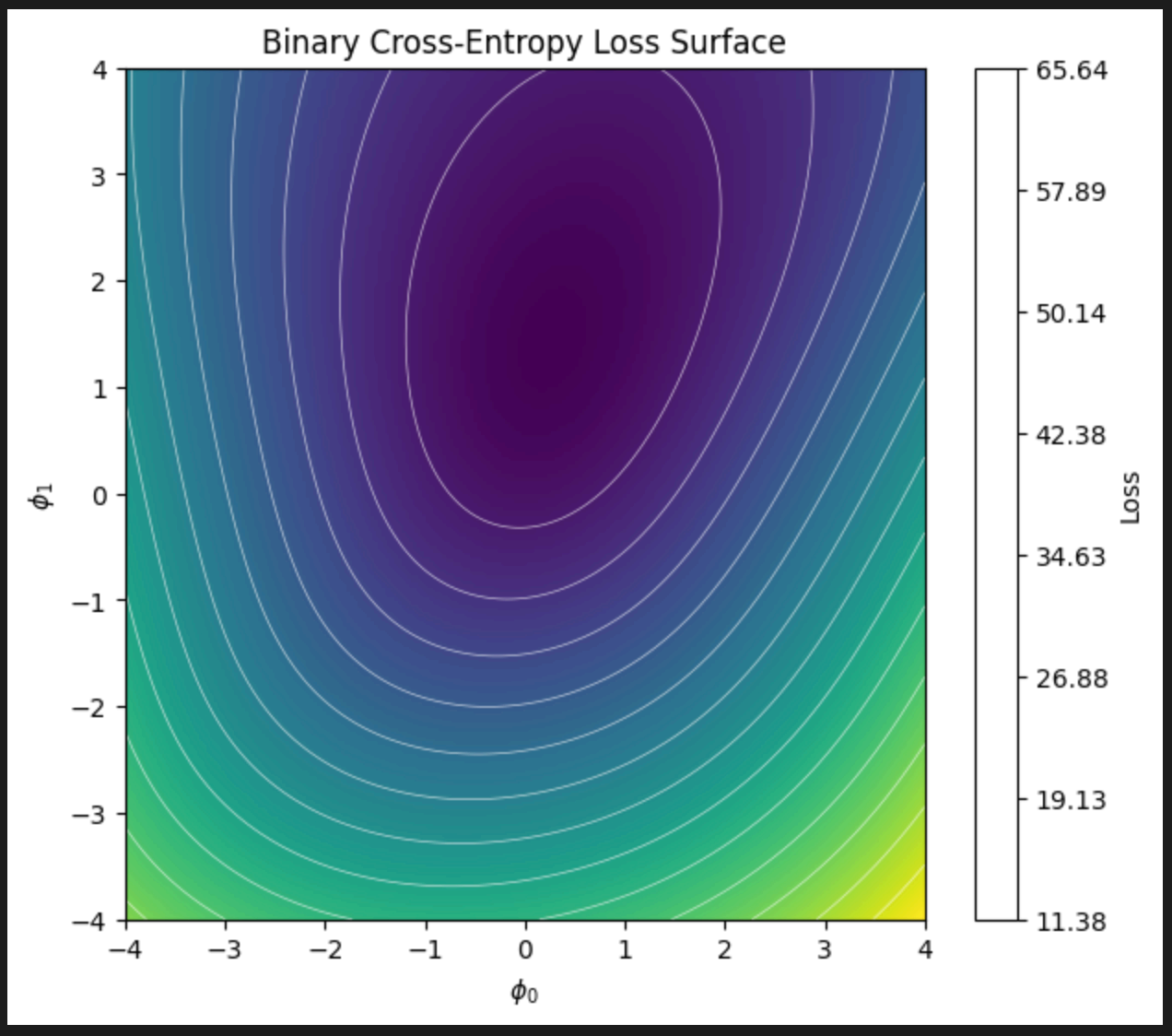
(v) The loss function seems to be convex based on the plot above. We can prove it by examining the Hessian matrix like we did in question 6.2.
Problem 6.5
Compute the derivatives of the least squares loss with respect to the ten parameters of the simple neural network model:
Think carefully about what the derivative of the ReLU function will be.
The derivative of the least squares loss function is given by:
The derivative of ReLU is:
We can write this as .
Then, the derivatives are:
and:
Problem 6.6
Which of the functions in figure 6.11 is convex? Justify your answer. Character each of the points 1-7 as (i) a local minimum, (ii) a global minimum, or (iii) neither.
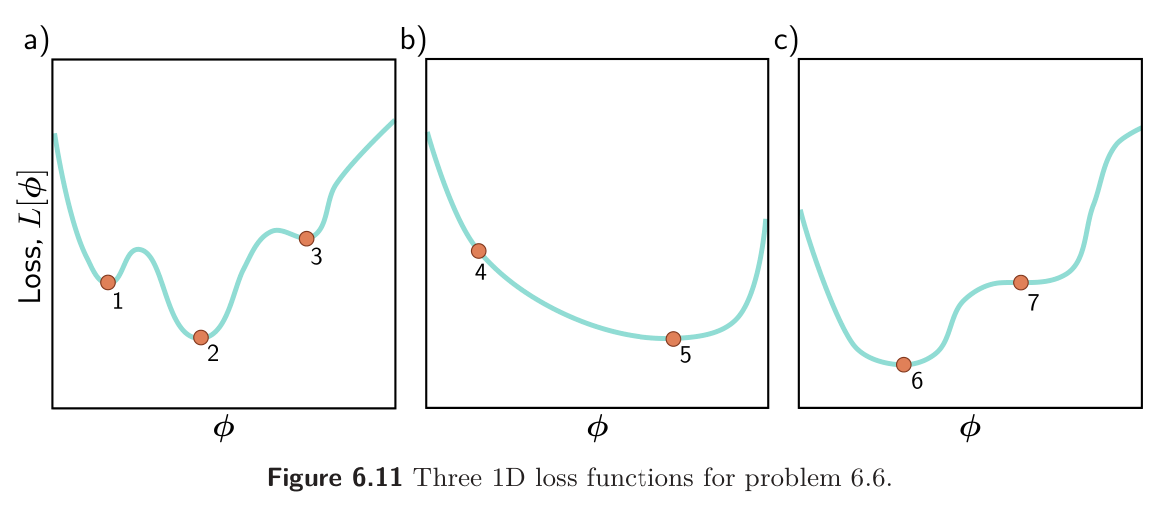
B is the only convex function; all chords lie below above the function. A is non-convex (a chord from 1 → 2 or 2 → 3 would be below the curve), C is non-convex (a chord from 6 → 7 would intersect/be below the curve).
Points:
- Local minimum
- Global minimum
- Local minimum
- Neither
- Global minimum
- Global minimum
- Neither (saddle point)
Problem 6.7
The gradient descent trajectory for path 1 in figure 6.5a oscillates back and forth inefficiently as it moves down the valley toward the minimum. It’s also notable that it turns at right angles to the previous direction at each step. Provide a qualitative explanation for these phenomena. Propose a solution that might help prevent this behavior.
The trajectory must turn at right angles. If the current direction still had any component pointing downhill (i.e. decreasing the function), we should logically keep going in that direction. However, we’re in a “curved valley” and just overshot the center, so continuing in the same direction would now move you uphill on the other side, so the gradient reverses direction sharply.
Solutions include Newton’s method (use second derivative to understand curvature of the loss landscape) or momentum.
Problem 6.8
Can (non-stochastic) gradient descent with a fixed learning rate escape local minima?
No - in a local minima the gradient will be zero or near zero so the non-stochastic gradient descent will just be stuck there as it has no reason to move.
Problem 6.9
We run the stochastic gradient descent algorithm for 1000 iterations on a dataset of size 100 with a batch size of 20. For how many epochs did we train the model?
Batch size of 20, total size 100 means that 1 epoch is 100/20 = 5 iterations. 1000/5 = 200 epochs.
Problem 6.10
Show that the momentum term (equation 6.11) is an infinite weighted sum of the gradients at the previous iterations and derive an expression for the coefficients (weights) of that sum.
Recall that the momentum update is given by
We want to unroll this sequence.
Thus, as , this sum approaches an infinite sum of the form:
where .
Problem 6.11
What dimensions will the Hessian have if the model has one million parameters?
The Hessian will be :