NeRF synthesizes novel of complex views by optimizing an underlying continuous volumetric scene function using a sparse set of input views.
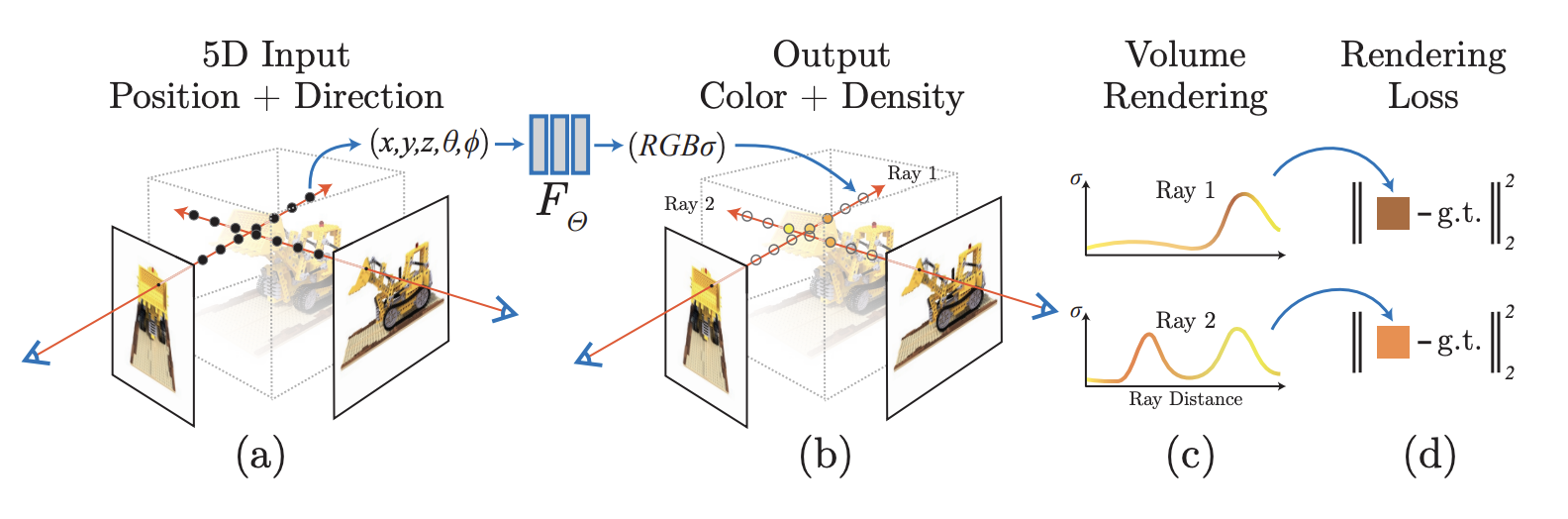
A scene is represented using a MLP, whose input is a single continuous 5D coordinate (spatial location and viewing direction ) and whose output is the volume density and view-dependent emitted radiance at that spatial location.
The loss function is just the total squared error between the rendered and true pixel colors.
I like this paper because of how clever it is in terms of data representation; they don’t use any architecture or function that’s super fancy, they just found a way to formulate the problem in a nice way.