Ensembling reduces the generalization gap between training and test data to build several models and average their predictions. This technique reliable improves test performance at the cost of training and storing multiple models and performing inference multiple times.
The assumption is that model errors are independent and will cancel out.
The model can be combined by:
- Taking the mean of the outputs (for regression problems)
- Taking the mean of the pre-softmax activations (for classification problems).
Alternatively, we can:
- Take the median of the outputs (for regression problems)
- Take the most frequent predicted class (for classification problems) to make the predictions more robust.
One way to train different models is just to use different random initializations. this may help in regions of input space far from the training data. Here, the fitted function is relatively unconstrained, and different models may produce different predictions, so the average of several models may generalize better than any single model.
A second approach is to generate several different datasets by re-sampling the training data with replacement and training a different model from each. This is known as bootstrap aggregating or bagging for short. It has the effect of smoothing out the data; if a data is not present in one training set, the model will interpolate from nearby points; hence, if that point was an outlier, the fitted function will be more moderate in this region.
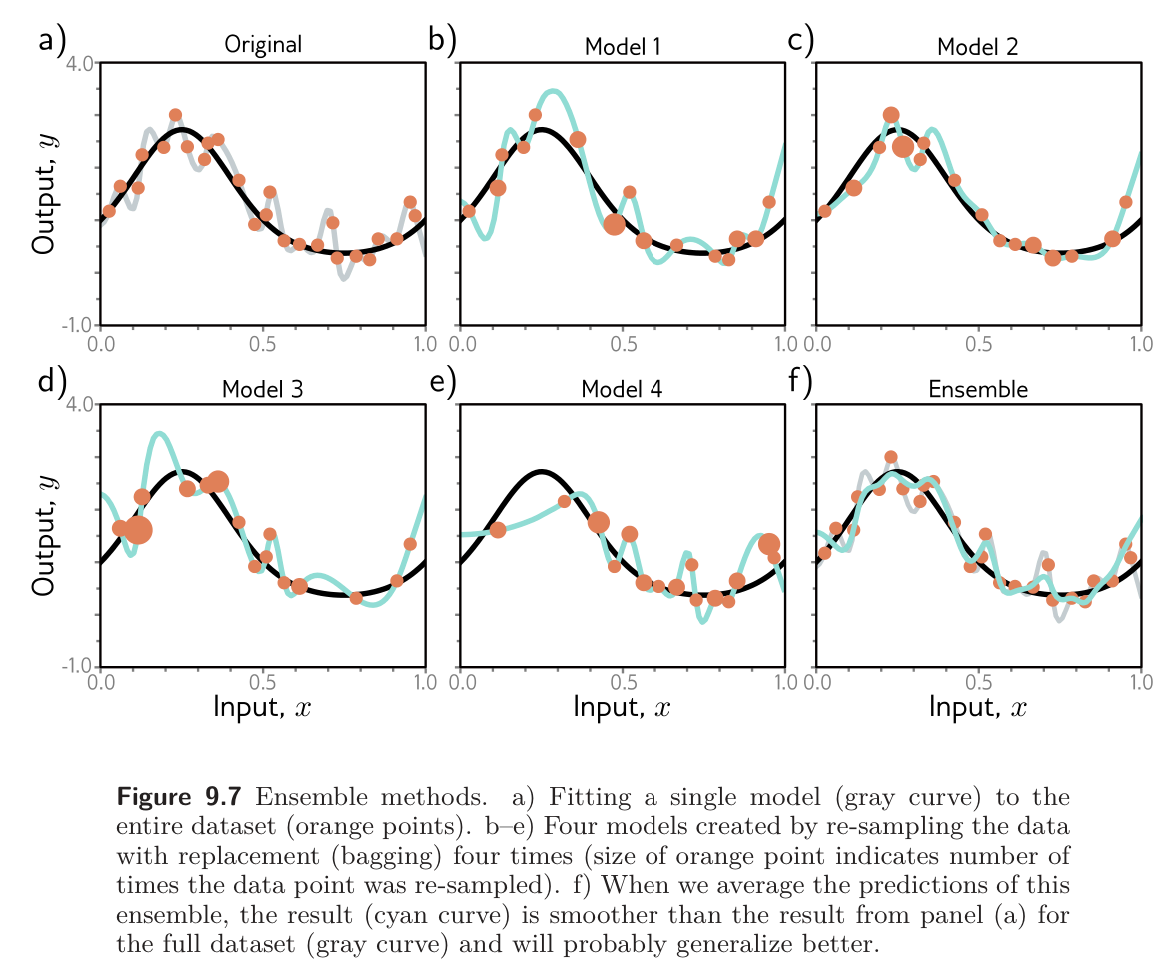
Other approaches include training models with different hyperparameters or training completely different families of models.