Residual blocks receive the output from the previous layer, modify it by passing it through some network layers, and add it back to the original input. An alternative is to concatenate the modified and original signals. This increases the representation size (in terms of channels for a convolutional network), but an optional subsequent linear transformation can map back to the original size (a 1x1 convolution for a convolutional network). This allows the model to add the representations together, take a weighted sum, or combine them in a more complex way.
The DenseNet architecture uses concatenation so that the input to a layer comprises the concatenated outputs from all previous layers. These are processed to create a new representation that is itself concatenated with the previous representation and passed to the next layer. This concatenation means that there is a direct contribution from earlier layers to the output, so the loss surface behaves reasonably.
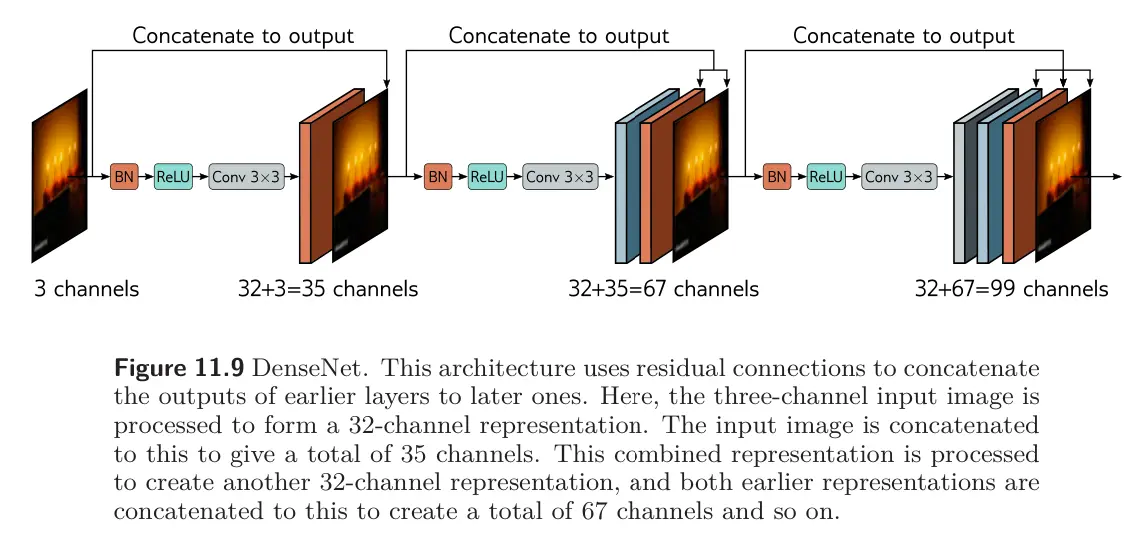
In practice, this can only be sustained for a few layers because the number of channels (and hence the number of parameters required to process them) becomes increasingly large. This can be alleviated by applying convolutions to reduce the number of channels before the next convolution is applied.
In a convolutional network, the input is periodically downsampled. Concatenation across the downsampling makes no sense since the representations have different spatial sizes. Consequently, the chain of concatenation is broken at this point, and a smaller representation starts a new chain. Additionally, another bottleneck convolution can be applied when the downsampling occurs to control the representation size further.
dl DenseNet ? Input to a layer consists of concatenated outputs from all previous layers.
+++