Consider a model with parameters that computes an output from . Instead of thinking about the model directly computing a prediction , we can shift perspective and consider the model as computing a conditional probability distribution , over possible outputs given .
The loss encourages each training output to have a high probability under the distribution , computed from the corresponding .
Conditional probability model examples
- a) Regression task, where the goal is to predict a real-valued output from the input based on training data (orange points). For each input value x, the model predicts a distribution over the output . The loss function aims to maximize the probability of the observed training outputs under the distribution predicted from the corresponding inputs .
- b) To predict discrete classes in a classification task, we use a discrete probability distribution, so the model predicts a different histogram over the four possible values of for each value of .
- c) To predict counts we use distributions defined over positive integers
- d) To predict directions , we use distributions defined over circular domains
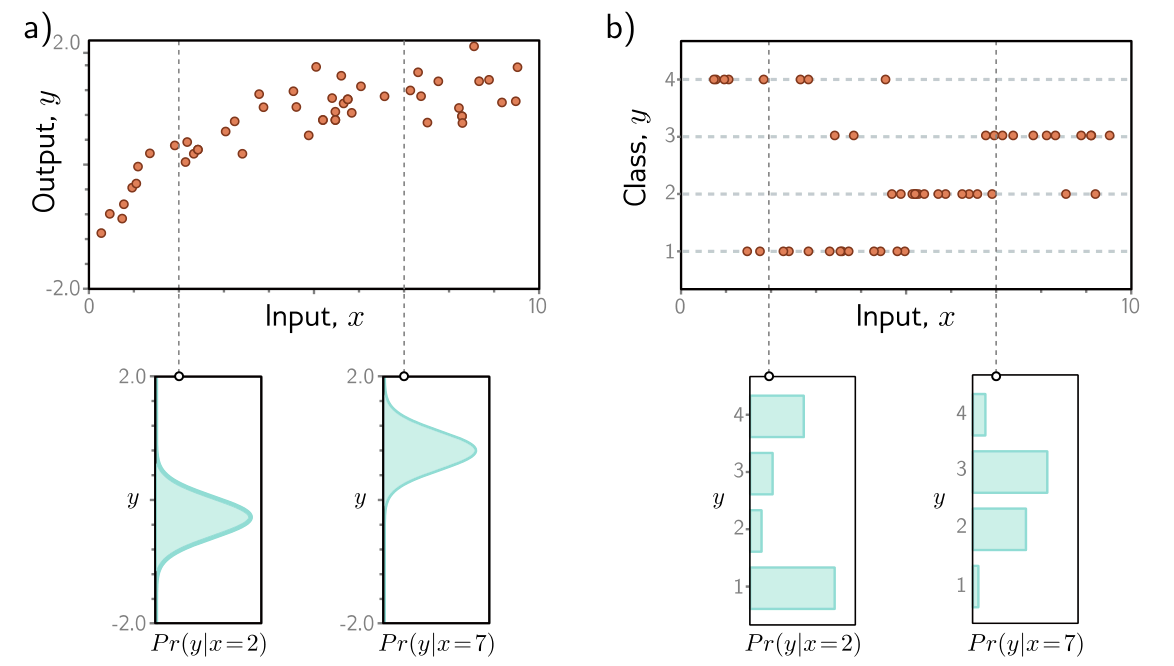
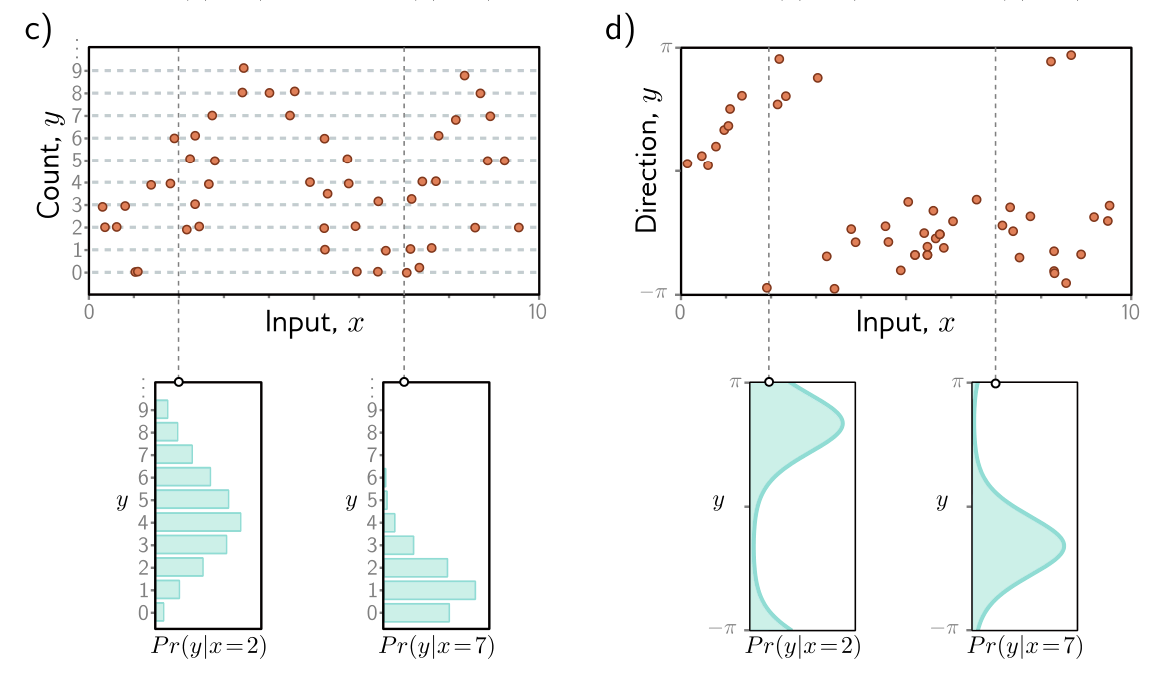
Computing a distribution over outputs
How exactly can a model be adapted to compute a probability distribution?
First, we choose a parametric distribution defined on the output domain . Then, we use the network to compute one or more of the parameters of this distribution.
For example, suppose the prediction domain is the set of real numbers, so . Here, we might choose the univariate normal distribution, which is defined on . This distribution is defined by the mean and variance , so . The model might predict the mean , and the variance could be treated as an unknown constant.
Inference
We use log-likelihood as a loss function to find the best parameters. At inference time, the network no longer predicts the outputs but instead determines a probability distribution over . However, we often want to use a point estimate rather than a distribution.
To do this, we return the maximum of the distribution
It’s usually possible to find an expression for this in terms of the distribution parameters predicted by the model. For example, in the univariate normal distribution, the maximum occurs at the mean .
Multiple Outputs
Often, we wish to make more than one prediction with the same model, so the target output is a vector. For example, we might want to predict a molecule’s melting and boiling point (multivariate regression), or the obstacle class at every point in an image (multivariate classification). While it’s possible to define multivariate probability distributions and use a neural network to model their parameters as a function of the input, it’s more usual to treat each prediction as independent.
Independence implies that we treat the probability as a product of variate terms for each element :
where is the -th set of network outputs, which describe the parameters of the distribution over . For example:
- To predict multiple continuous variables , we use a normal distribution for each , and the network outputs predict the means of these distributions.
- To predict multiple discrete variables , we use a categorical distribution for each . Here, each set of network outputs predicts the values that contribute to the categorical distribution for .
When we minimize the negative log-likelihood, this product becomes a sum of terms:
where is the -th output from the -th training example.
To make two or more prediction types simultaneously, we similarly assume the errors in each are independent.
- Example: To predict wind direction and strength, we might choose the von Mises distribution (defined on circular domains) for the direction, and the exponential distribution (defined on positive real numbers) for the strength.
The independence assumption implies that the joint likelihood of the two predictions if the product of individual likelihoods. These terms will become additive when we compute the negative log-likelihood.